-
머신 러닝으로 금 시세를 예측 해보자 feat. Prophet모델 구축 2020. 4. 1. 10:56
1. Prophet에 대한 간단한 설명
2. Prophet 모델 구축
3. Prophet 파라미터 조정
1. Prophet에 대한 간단한 설명
Prophet은 Facebook에서 만든 시계열 예측 package이다. 장점은 간단하고, 성능이 좋다는 점이다!
ARIMA와 같이 데이터의 정상성을 확보할 필요도 없으며, 파라미터가 직관적이라 튜닝이 편리하다.
또한 자동으로 변경 포인트를 찾아 fitting을 하기 때문에 주기가 일정하지 않은 데이터에 대해서도 예측이 가능하다.
https://facebook.github.io/prophet/
Prophet
Prophet is a forecasting procedure implemented in R and Python. It is fast and provides completely automated forecasts that can be tuned by hand by data scientists and analysts.
facebook.github.io
알고리즘과 사용법의 대부분의 설명은 「어쩐지 오늘은」 님의 블로그에서 확인할 수 있다. 간단히는 추세(trend), 계절성(seasonality), 특정 이벤트(holiday)를 기준으로 예측을 한다. 하지만 고정된 추세가 아니고 확률적으로 변경 포인트를 찾아 추세를 조정함으로써 비선형적인 데이터의 설명도 가능해진다.
2. Prophet 모델 구축
Prophet을 사용하기 위해서는 fbprophet을 인스톨한다.
pip install fbprophet사용법도 상당히 간단하다. package를 불러오고
import pandas as pd import matplotlib.pyplot as plt from fbprophet import ProphetProphet()으로 새로운 모델 객체화한다. 예시로 금 시세 분석을 하므로 ARIMA때와 같은 금 시세 데이터를 준비한다.
m = Prophet()plt.plot(gold_price_series) plt.show()
이제 데이터를 모델에 넣고 fitting만 해 주면 된다. 주의할 점은 데이터의 columns이름을 시간은 ds, 데이터 값은 y로 지정해야 한다는 점이다.
prophet_series = pd.DataFrame(list(zip(gold_price_series.index, gold_price_series['price(USD)'])),columns=['ds', 'y']) m.fit(prophet_series)결과를 확인해 보자.
forecast = m.predict(prophet_series) fig, ax = plt.subplots(figsize=(16,5)) m.plot(forecast, ax=ax) plt.show()
검은 점은 실측치, 하늘색 선은 예측치, 연한 하늘색 영역은 신뢰 구간(디폴트는 80%)을 나타낸다. 범례가 없어서 같은 그래프를 다시 그려 봤다.
fig, ax = plt.subplots(figsize=(16,5)) plt.plot(forecast['ds'].dt.to_pydatetime(),forecast['yhat'], label='forecast', color='blue') plt.plot(prophet_series['ds'].dt.to_pydatetime(),prophet_series['y'], label='observations ', color='black') plt.fill_between(forecast['ds'].dt.to_pydatetime(), forecast['yhat_upper'],forecast['yhat_lower'],color='skyblue',label='80% confidence interval') plt.legend() plt.xlabel('date') plt.ylabel('price(USD)') plt.show()
plot_components로 추세, 계절성을 파악할 수 있다.
m.plot_components(forecast,figsize=(16,10)) plt.show()
2021년까지의 금 시세를 예측해 보자. 먼저 하기의 코드로 미래 데이터를 만든다. 표의 맨 밑을 보면, preiods에서 지정한 바와 같이 1년 뒤인 2021년 3월 30일까지의 날짜 데이터가 생긴 것을 알 수 있다.
future = m.make_future_dataframe(periods=365)
기존의 데이터로 fitting 한 모델에 미래 데이터(future)를 넣어보자.
forecast = m.predict(future) fig, ax = plt.subplots(figsize=(16,5)) plt.plot(forecast['ds'].dt.to_pydatetime(),forecast['yhat'], label='forecast', color='blue') plt.plot(prophet_series['ds'].dt.to_pydatetime(),prophet_series['y'], label='observations ', color='black') plt.fill_between(forecast['ds'].dt.to_pydatetime(), forecast['yhat_upper'],forecast['yhat_lower'],color='skyblue',label='80% confidence interval') plt.legend() plt.xlabel('date') plt.ylabel('price(USD)') plt.show()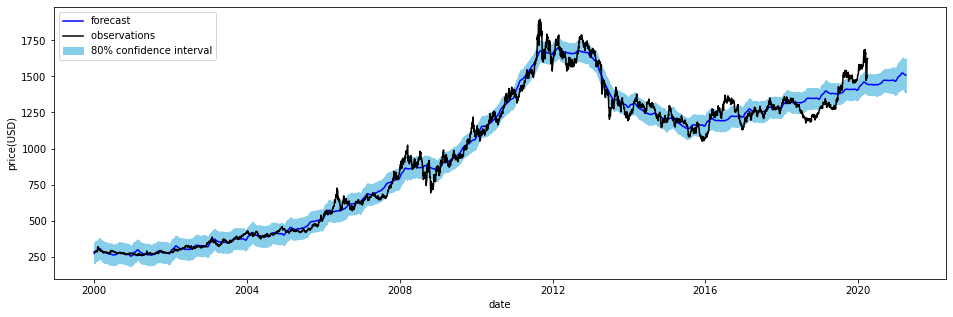
2021년의 데이터의 예측 값이 나오는 것을 확인할 수 있다. 예측 결과 테이블을 확인해 보면, yhat이 예측치, yhat_upper와 yhat_lower 가 신뢰 구간임을 확인 할 수 있다.
print(forecast)
3. Prophet 파라미터 조정
Prophet에서 조정이 가능한 파라미터는 크게 5가지로 나눌 수 있다.
- 데이터의 상한 하한의 설정
- 변동 포인트의 설정
- 계절성의 조정
- 특별 이벤트의 추가
- 신뢰 구간의 조정
- 데이터의 상한 하한의 설정
우리는 시계열 데이터가 어느 정도 이상은 커지지 않는다 혹은 작아지지 않는다를 설정할 수 있다. 예를 들어 전세계의 인구를 바탕으로 생각했을 때 자동차 판매량은 어느정도 이상은 커지지 않는다는 사실이 명확하다면, 데이터를 상한을 정할 수 있을 것이다.
데이터의 상하한을 설정하는 법은, 먼저 모델의 growth파라미터를 logistic으로 설정하고, 데이터 테이블에 ['cap'], 하한치는 ['floor']라는 열을 만들고 설정하면 된다. 하기의 코드는 상한은 2000, 하한은 250으로 설정했다.(상하한 모두를 설정할 필요는 없으며, 하나만 설정해도 된다.)
m = Prophet(growth = 'logistic') prophet_series = pd.DataFrame(list(zip(gold_price_series.index, gold_price_series['price(USD)'])),columns=['ds', 'y']) prophet_series['cap'] = 2000 prophet_series['floor'] = 250 m.fit(prophet_series) forecast = m.predict(prophet_series) fig, ax = plt.subplots(figsize=(16,5)) m.plot(forecast, ax=ax) plt.show()
그래프를 보면 그래프의 위아래에 검은 점선이 생긴 것을 알 수 있는데 이 점선이 우리가 설정한 상하한 선이 된다. 예측은 언제나 이 점선의 안쪽에서 이루어진다. 위의 예시는 상하한을 일정 치로 두었지만, 일정 치를 넣을 필요는 없다. 예를 들어 시장의 전체 크기가 일정 성장률로 성장한다면, 시간에 따른 상한치를 조정하는 것도 가능하다. 하기는 그냥 상하 한치의 설정이 변동이 가능하다는 예시이다.
m = Prophet(growth = 'logistic') prophet_series = pd.DataFrame(list(zip(gold_price_series.index, gold_price_series['price(USD)'])),columns=['ds', 'y']) prophet_series['cap'] = prophet_series['y'] * 1.1 prophet_series['floor'] = prophet_series['y'] * 0.9 m.fit(prophet_series) forecast = m.predict(prophet_series) fig, ax = plt.subplots(figsize=(16,5)) m.plot(forecast, ax=ax) plt.show()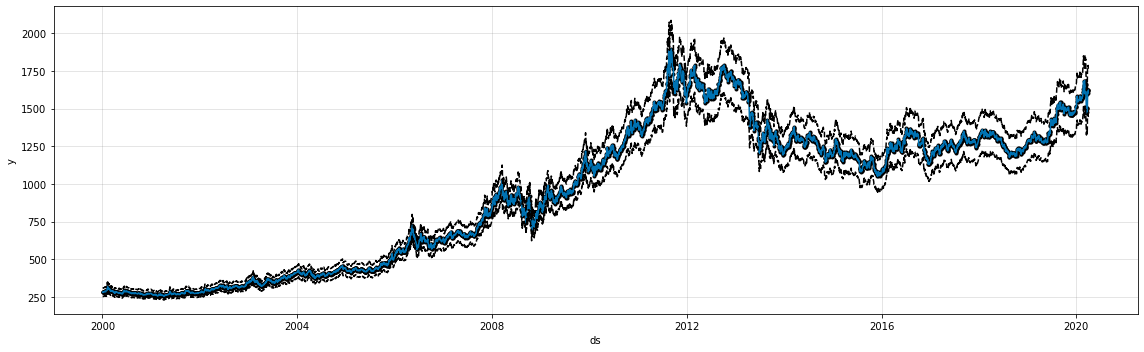
- 변동 포인트의 설정
위에서 설명한 바와 같이 Prophet은 자동으로 트렌드의 변동 포인트를 찾아낸다. 통계적으로 적절하다고 생각하는 구간으로 나누어 각 구간별로 fitting을 새로 하는 방식이다. 우리는 이러한 변동 포인트의 수, 찾는 기준이 되는 데이터의 길이, 어느 정도의 변화가 있으면 변동점으로 할 것인지(flexibility)등을 조정해서 모델을 튜닝할 수 있다.
먼저 모델에서 변동을 찾아 나눈 구간을 확인해 보자.
from fbprophet.plot import add_changepoints_to_plot fig = m.plot(forecast) a = add_changepoints_to_plot(fig.gca(), m, forecast)
빨간 점선이 모델이 변동점으로 잡은 포인트이다. 각 구간에서는 빨간 직선이 선형적으로 연결돼 있는 것을 확인할 수 있다. 이러한 선형 직선에 계절성, 휴일, 잔차 등을 넣은 것이 모델의 예측값이 된다. 먼저 prophet은 전체 데이터에서 이러한 변동점을 찾는 것이 아니가 overfitting을 피하기 위해 학습 데이터의 앞부분 80%의 데이터만을 사용한다. 이 범위는 모델의 하이퍼 파라미터인 changepoint_range를 바꾸면 조정이 가능하다. 하기의 코드는 앞의 50%만을 사용하는 경우의 예시이다.
m = Prophet(changepoint_range=0.5) m.fit(prophet_series) forecast = m.predict(prophet_series) fig = m.plot(forecast) a = add_changepoints_to_plot(fig.gca(), m, forecast)
또한 변동점을 찾는 유동성 flexibility)도 변경이 가능한데, changepoint_prior_scale의 하이퍼 파라미터의 값을 올리면 좀 더 유동적으로 찾는다(->데이터에 오버 피팅 우려가 있다)
m = Prophet(changepoint_prior_scale=0.5) m.fit(prophet_series) forecast = m.predict(prophet_series) fig = m.plot(forecast) a = add_changepoints_to_plot(fig.gca(), m, forecast)
반대로 이 값을 낮추면 변동점을 찾는 유동성을 낮출 수 도 있다.(->언더 피팅에 주의)
m = Prophet(changepoint_prior_scale=0.001) m.fit(prophet_series) forecast = m.predict(prophet_series) fig = m.plot(forecast) a = add_changepoints_to_plot(fig.gca(), m, forecast)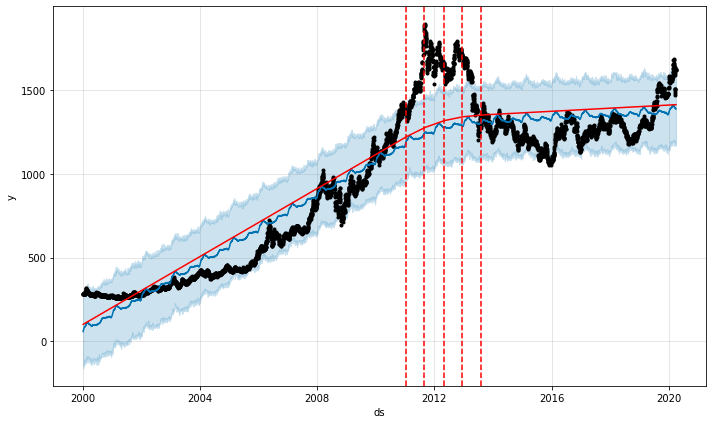
이러한 변동점은 지정한 changepoint_prior_scale에 따라 자동적으로 그 숫자가 정해진다. 이러한 숫자를 지정하고 싶은 경우
n_changepoints 파라미터의 숫자를 바꾸면 된다. 또한 changepoints로 특정 날짜를 변동점으로 지정하는 것도 가능하다.
- 계절성의 조정
위의 변동점 조정은 트렌드의 변동점을 설정하는 파라미터라면 하기의 파라미터는 계절성을 조정하는 파라미터이다.
yearly_seasonality, weekly_seasonality, daily_seasonality
계절성의 추정은 푸리에 급수의 부분합을 이용하는데 몇 차수까지의 합을 이용할지는 정하는 파라미터다. 이 값을 올리면 계절성의 fitting이 더 복잡해진다. 왼쪽의 그래프가 yearly_seasonality가 10인 경우(default)이고 왼쪽의 그래프가 20으로 올린 경우이다.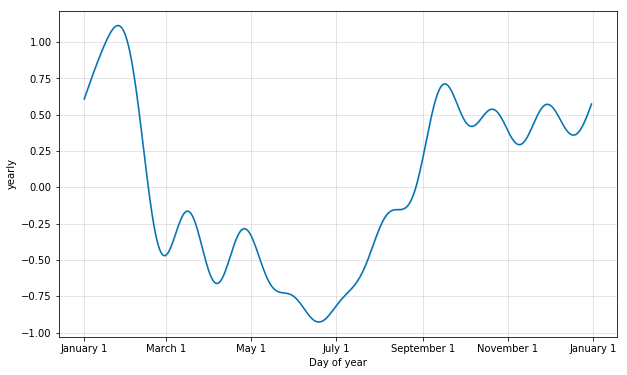

seasonality_mode
계절성의 분산이 시간에 따라 변동하는 경우 seasonality_mode를 multiplicative로 설정할 필요가 있다.
왼쪽 그래프는 seasonality_mode를 additive(defualt)인 경우로, 1950년 부근은 계절성을 과하게 추정하고, 1960년대에는 실 데이터보다 적게 추정하는 것을 알 수 있다. 반면, 오른쪽 그래프는 seasonality_mode를 multiplicative로 변경하여, 좀 더 데이터에 맞는 모델이 구축된 것을 확인할 수 있다.

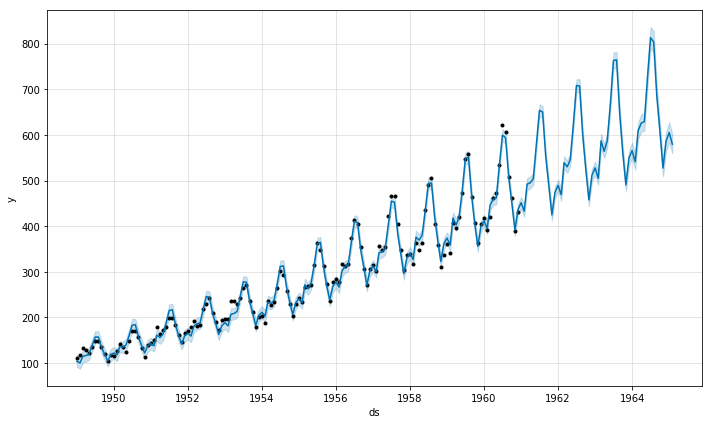
seasonality_prior_scale
전체 데이터에서의 계절성의 영향도를 조정하는 파라미터로 값을 낮추면, 계절성의 영향도를 낮출 수 있다.(default 10)
add_seasonality
파라미터라기보다는 새로운 커스터마이즈 한 계절성을 추가하는 메서드이다.
m = Prophet(weekly_seasonality=False) m.add_seasonality(name='monthly', period=30.5, fourier_order=5) forecast = m.fit(df).predict(future) fig = m.plot_components(forecast)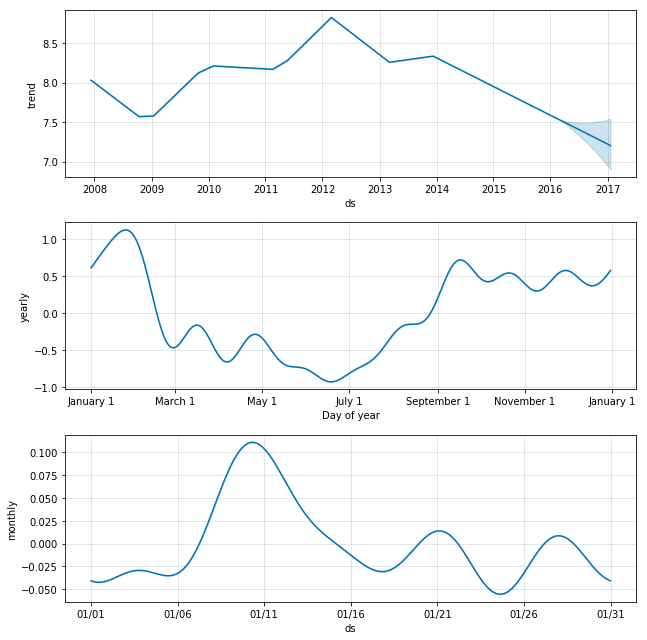
- 특별 이벤트의 추가
하기의 코드와 같이 holidays에 특별한 날짜의 이벤트, 휴일 등을 넣는 것이 가능하다.
playoffs = pd.DataFrame({ 'holiday': 'playoff', 'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16', '2010-01-24', '2010-02-07', '2011-01-08', '2013-01-12', '2014-01-12', '2014-01-19', '2014-02-02', '2015-01-11', '2016-01-17', '2016-01-24', '2016-02-07']), 'lower_window': 0, 'upper_window': 1, }) superbowls = pd.DataFrame({ 'holiday': 'superbowl', 'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']), 'lower_window': 0, 'upper_window': 1, }) holidays = pd.concat((playoffs, superbowls)) m = Prophet(holidays=holidays) forecast = m.fit(df).predict(future)그 외에 seasonality_prior_scale와 같이 holidays_prior_scale로 holidays의 강도 조절이 가능하며, 하기와 같이 추가적인 설명 변수를 넣어 linear regression 항목을 추가할 수 있다.
def nfl_sunday(ds): date = pd.to_datetime(ds) if date.weekday() == 6 and (date.month > 8 or date.month < 2): return 1 else: return 0 df['nfl_sunday'] = df['ds'].apply(nfl_sunday) m = Prophet() m.add_regressor('nfl_sunday') m.fit(df) future['nfl_sunday'] = future['ds'].apply(nfl_sunday) forecast = m.predict(future) fig = m.plot_components(forecast)add_regressor의 강도는 위의 holidays_prior_scale와 같이 연동된다.
holidays와 add_regressor은 비슷해 보이지만, add_regressor는 1, 0와 같이 binary일 필요가 없이, 연속 숫자를 넣는 것이 가능하다.
- 신뢰 구간의 조정
신뢰 구간의 조정
신뢰 구간은 조정은 interval_width로 할 수 있다. 하기는 95% 신뢰 구간으로 변경한 코드.
forecast = Prophet(interval_width=0.95).fit(df).predict(future)계절성의 신뢰구간을 구하고 싶으면, mcmc_sample을 지정해야 한다. 지정하는 숫자는 계절성의 신뢰구간을 구하기 위해 몇 개의 샘플을 사용하겠느냐는 것을 정하는 것이다.
m = Prophet(mcmc_samples=300) forecast = m.fit(df).predict(future) fig = m.plot_components(forecast) plt.show()
'모델 구축' 카테고리의 다른 글
머신 러닝으로 금 시세를 예측해 보자 feat. LSTM (2) 2020.04.13 머신 러닝으로 금 시세를 예측 해보자 feat. ARIMA (3) 2020.03.31